Chapter 4 Análisis exploratorio y descriptivo II
4.1 Escala de medida
Es una manera de valorar los datos observados desde los datos cuantitativos o datos cualitativos.
4.1.1 Escala nominal
Corresponde a valores de tipo cualitativo, sin ningún orden y por lo general son pocos los niveles o valores. No se puede realizar operaciones elementales, solo permite conteo.
4.1.2 Escala ordinal
Las clases o categorías que se asigna a los observado de tipo cualitativo, mantiene una cierta jerarquía sin importar su distanciamiento y son conocidos como variables seudo cuantitativas.
4.2 Aplicación
Para establecer la identificación y diferencias en las medidas, se utilizará el investario de maíz.
Se registró información de variables morfológicas del maíz en dos localidades y ocho tratamientos.
Tratamiento
T1 T2 T3 T4 T5 T6 T7 T8
52 49 43 51 55 54 42 54 Localidad
L1 L2
188 212 PAE
Ausente o muy débil Débil Media Fuerte
93 152 85 70
Muy fuerte
0 La descripción permite indicar lo siguiente:
Escala nominal
- Tratamiento
- Localidad
Escala ordinal
- Pigmentación antociánica de los estigmas (PAE).
Escala de intervalo
- No se registran variables en escala intervalo.
Escala de razon
- Hojas por planta (HPP).
- Granos por mazorca (GPM).
- Longitud de grano (LG).
- Ancho de grano (AG).
- Peso de mazorca (PM).
Su identificación de algunas medias, permite agrupar, y son considerados como factores.
- Tratamiento
- Localidad
- Pigmentación antociánica de los estigmas (PAE).
4.2.1 Medidas estadísticas
Para el ejemplo, utilizar la moda como medida expresiva (representativa) para las variables Localidad y Tratamiento. En la variable PAE, que es ordinal, la medida más relevante y expresiva es la mediana.
4.2.2 Representación de las medidas en gráficos.
Es importante caracterizar el tipo de medida en su escala definida.
Distribución de los tratamientos
op <- par(mar = c(4,10,2,2))
tratamientos <- table(maiz3$Tratamiento)
barplot(tratamientos, horiz = FALSE, density = 15,
col = "blue", las = 2)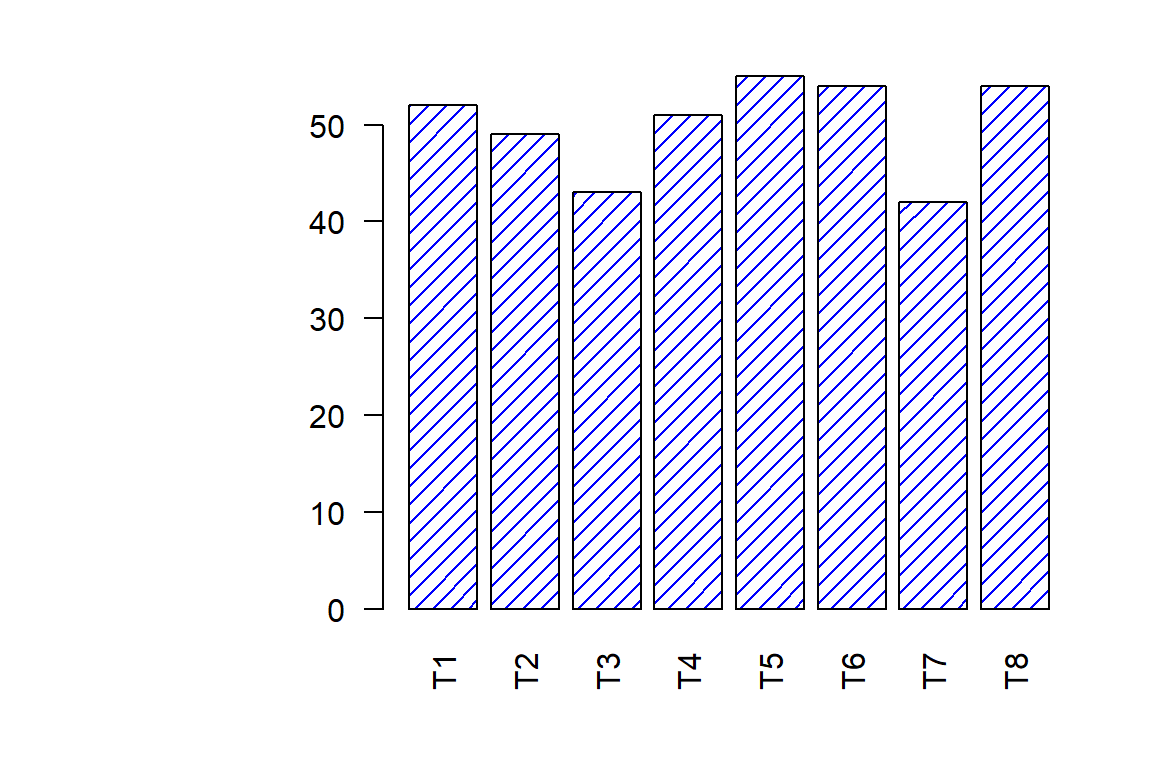
par(op)
op <- par(mar = c(0,0,0,0))
pie(tratamientos)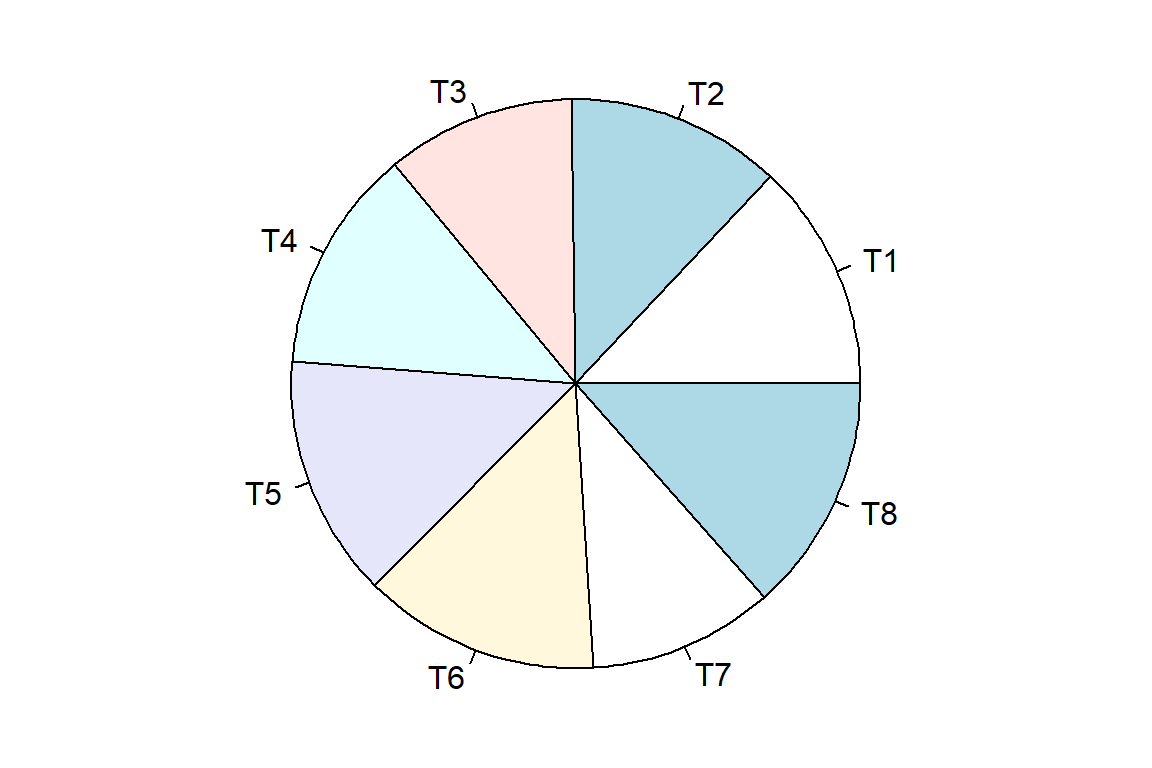
par(op)En el caso de la escala ordinal, debe tener presente el orden (ascendente o descendente).
op <- par(mar = c(4,4,2,2))
PAE <- table(maiz3$PAE)
barplot(PAE, horiz = TRUE, density = 15,
col = "blue", las = 2)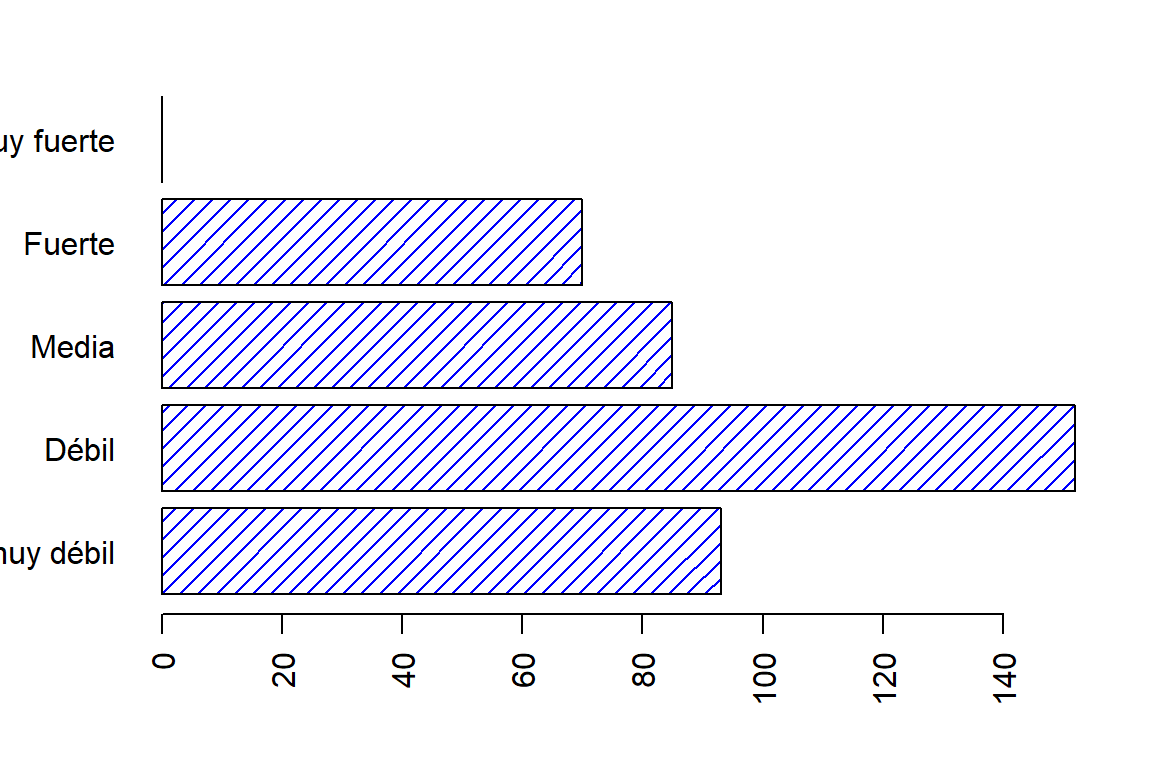
par(op)En el caso de variable discreta en datos agrupados, el gráfico debe ser de líneas verticales para cada valor.
Para este caso simulamos datos de un comportamiento binomial, como número de frutos de mango defectuosos en 30 cajas de 5 unidades observadas cada una (probabilidad de éxito de 0.3)
op <- par(mar = c(4,4,2,2))
x <- rbinom(30,5,0.3)
y <- table(x)
plot(y)
points(as.numeric(names(y)),y,pch=20,cex = 2)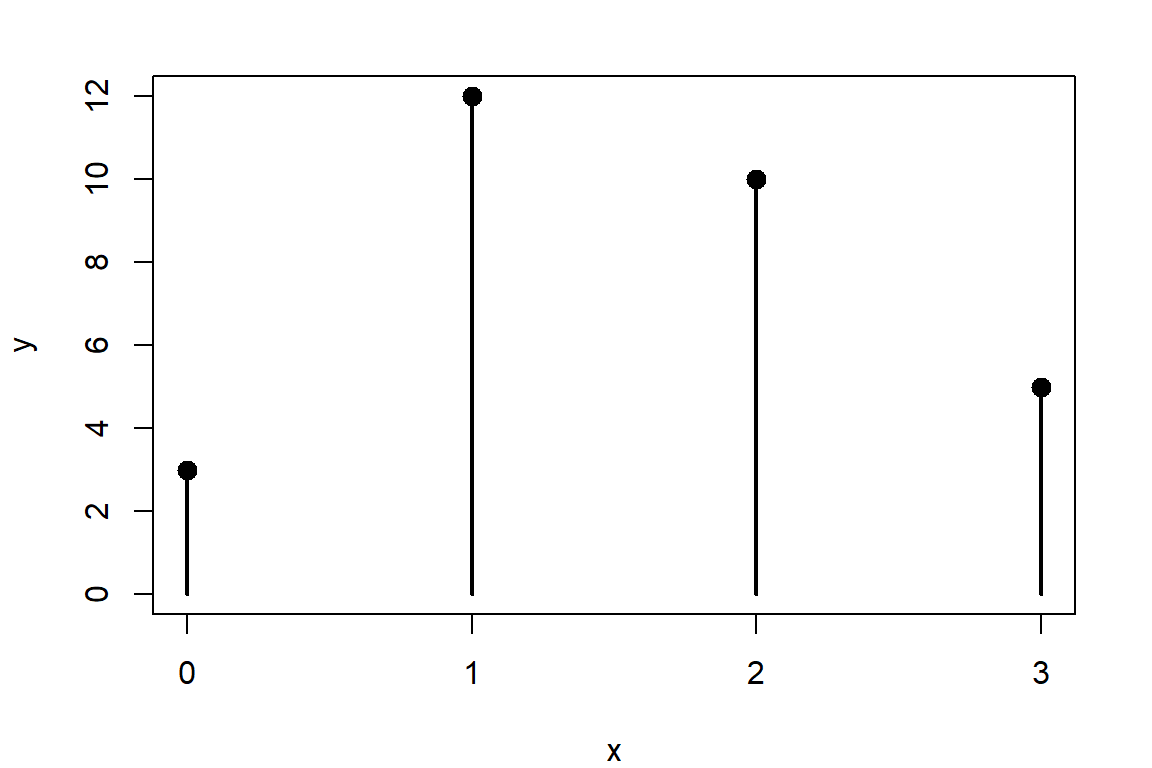
par(op)En el caso de variables continuas que corresponden a la escala de razón, los, los histogramas, diagramas de cajas y puntos son las más utilizadas.
Para mostrar estos gráficos se utilizará la longitud y el ancho de los granos en el inventario muestreado.
op <- par(mar = c(4,4,2,2))
Localidad1 <- subset(maiz3,maiz3$Localidad=="L1")
pairs(Localidad1[,c(5,6)])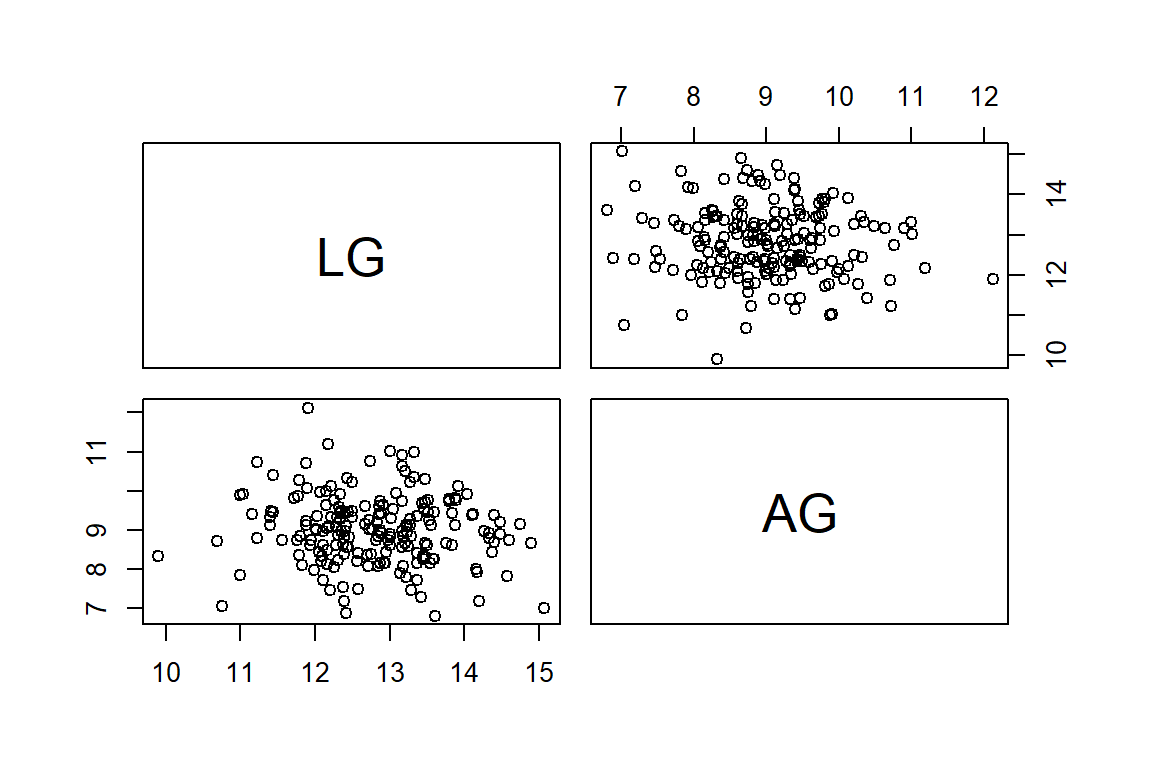
par(op)Se observa que la relación entre LG y AG es muy débil, no existe un patrón que indique una relación fuerte entre las variables LG y AG.
Los histogramas y el diagráma de cajas (Tukey) permite una mejor descripción.
op <- par(mar = c(4,4,2,2))
h1 <- hist(Localidad1$LG, main = "Longitud de grano en la localidad 1")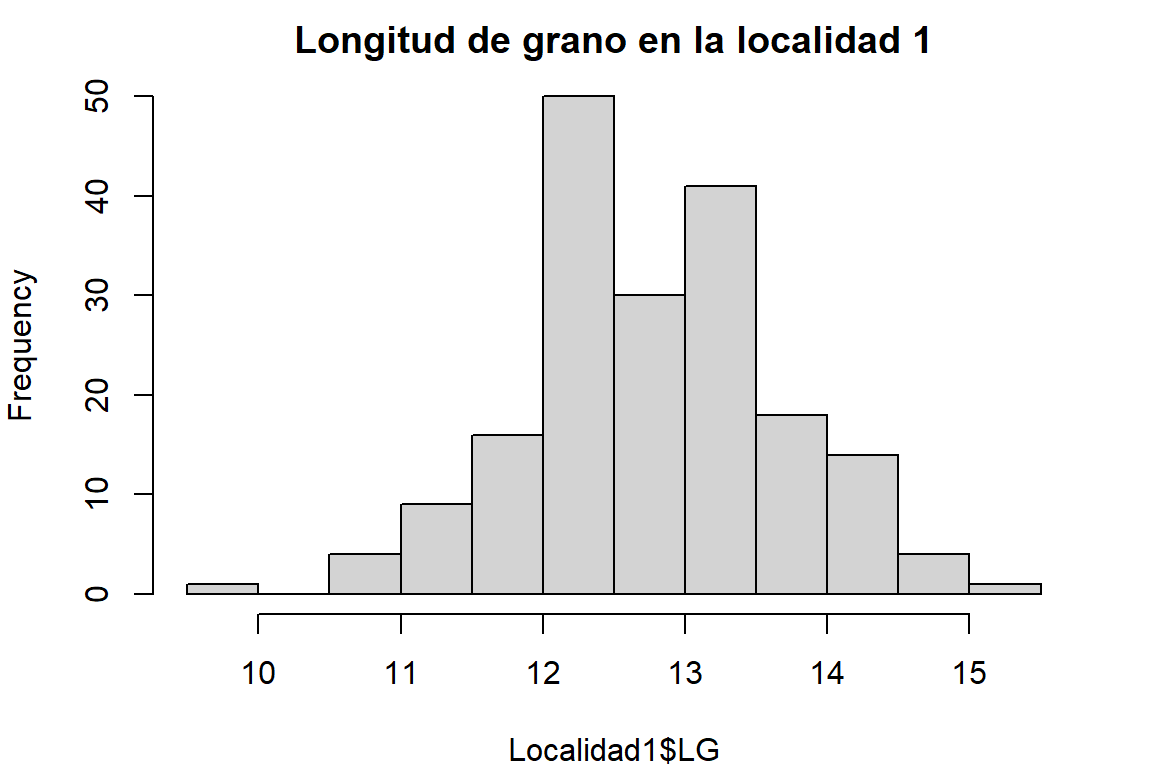
h2 <- hist(Localidad1$AG, main = "Ancho de grano en la localidad 1")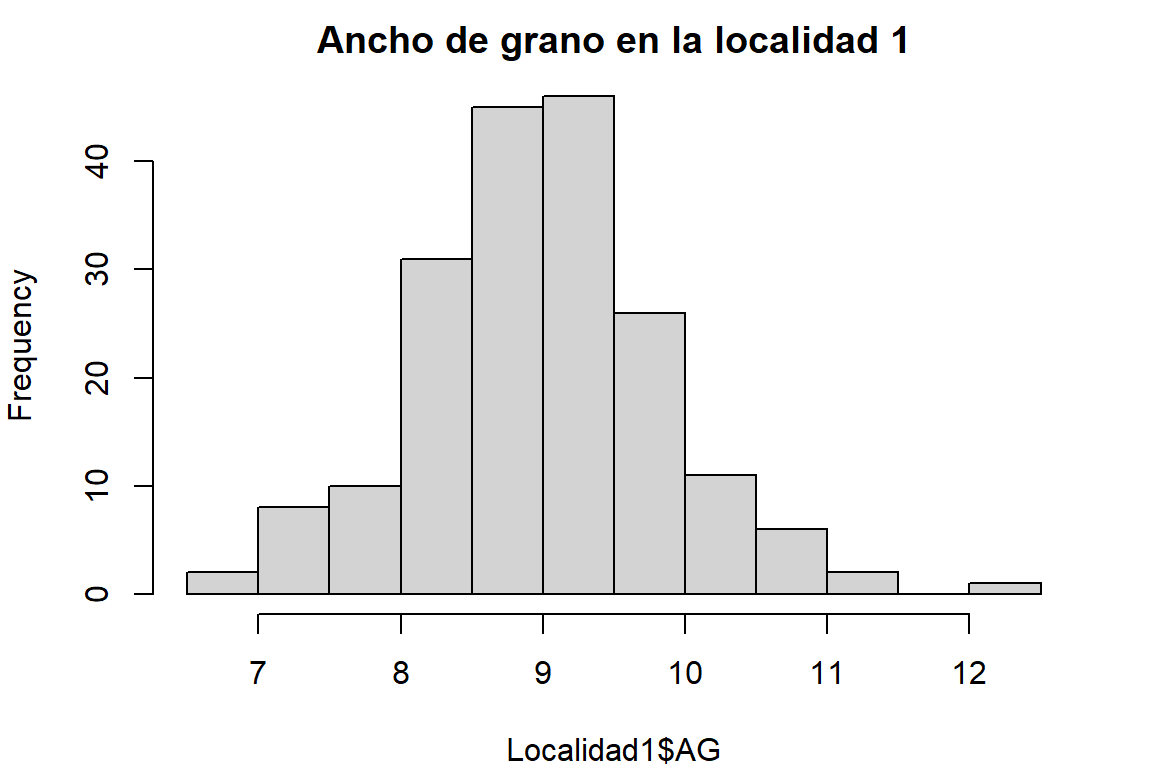
par(op)Diagráma de cajas para la Longitud de grano y el ancho de grano de todos los tratamientos
op <- par(mar = c(4,4,2,2))
b1 <- boxplot(LG ~ Tratamiento, data = Localidad1, xlab = "", main = "Longitud de grano en la localidad 1")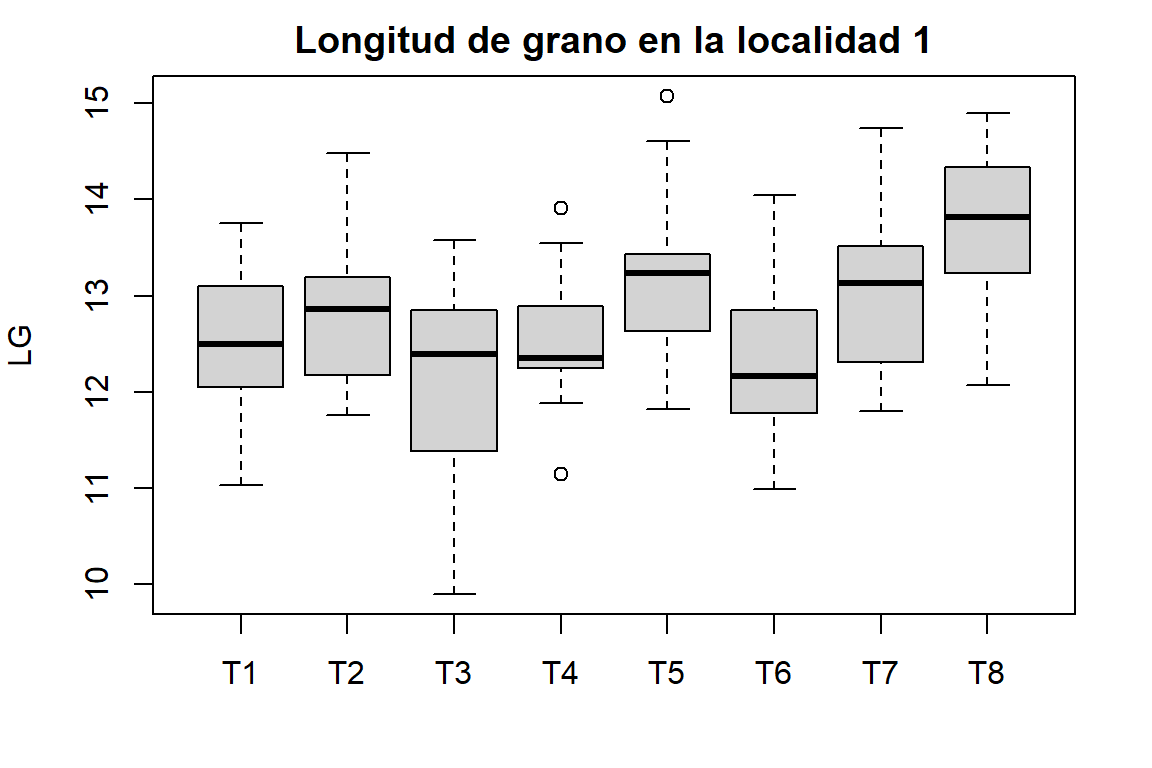
b2 <- boxplot(AG ~ Tratamiento, data = Localidad1, xlab = "", main = "Ancho de grano en la localidad 1")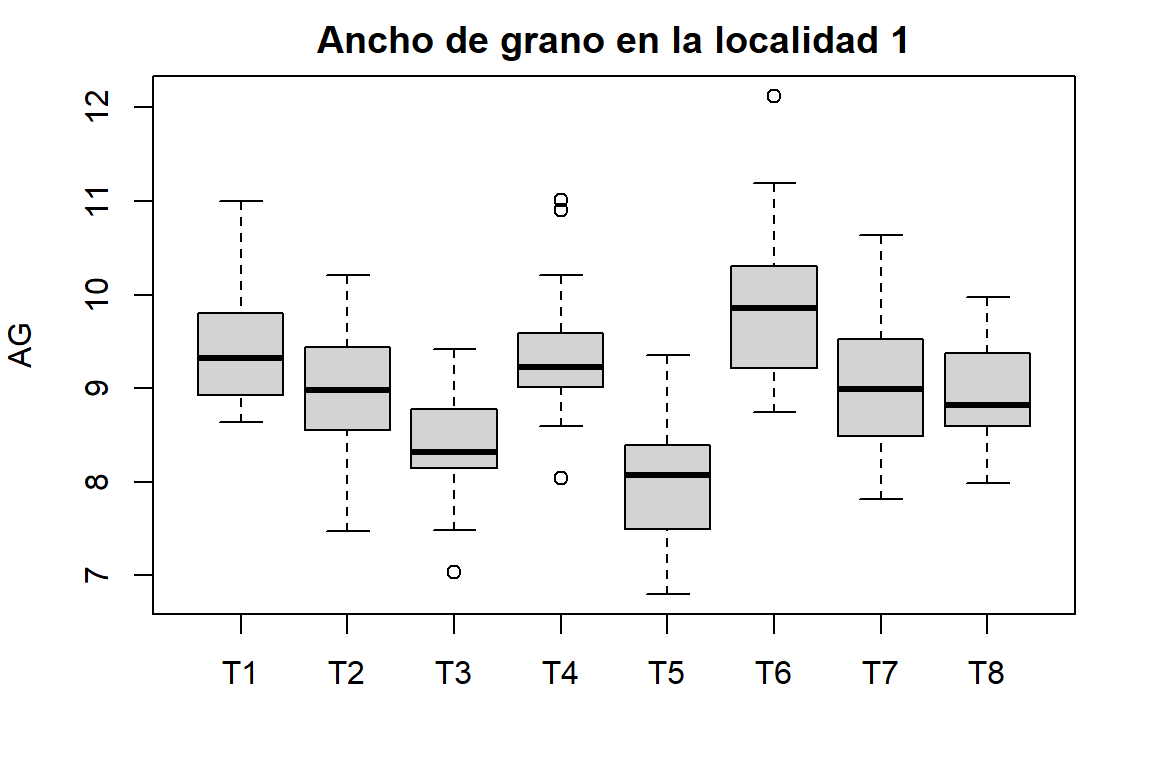
par(op)